Agent Newsletter
Get Agentic Newsletter Today
Subscribe to our newsletter for the latest news and updates
Cost-efficient open-source MoE model rivaling GPT-4o in reasoning and math tasks
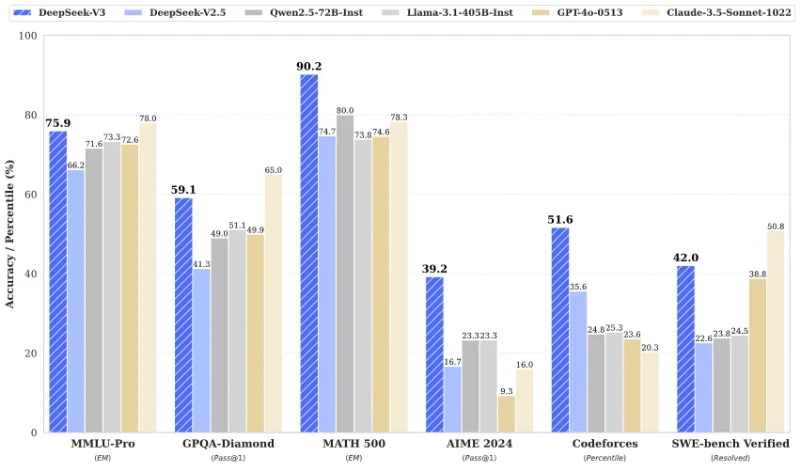
DeepSeek-V3 is a 671-billion-parameter Mixture-of-Experts (MoE) model with 37B parameters activated per token. It excels in coding, mathematics, and multilingual tasks, outperforming leading open-source models like Qwen2.5-72B and Llama-3.1-405B, and matches closed-source models like GPT-4o and Claude-3.5-Sonnet in benchmarks. Trained on 14.8 trillion tokens using FP8 mixed precision, it achieves state-of-the-art efficiency with a 128K context window and 3x faster generation speed compared to its predecessor

PoseUp.ai is an AI-powered photo enhancement tool that transforms ordinary photos into professional-quality images.
Matches local hardware to compatible Gemma 4 AI model versions.

Advanced AI for coding, reasoning, and computer interaction with a 200K context window.

A unified AI model combining logical reasoning with visual imagination

Powerful, Transparent, and Efficient Open-Source Code Models for Next-Generation Programming

Access and run Google's Gemma 4 open-source large language model.
Turn lectures, podcasts, and voice notes into clean text with an AI-powered MP3 to text converter

